

Recent advances in Agentic AI have increased the likelihood of cyberattacks cascading into systemic risk. Unlike earlier generations of software systems, Agentic AI systems can autonomously identify and exploit vulnerabilities that defenders may not even suspect exist — and do so at unprecedented speed and with substantially lower human effort. Together, these developments make cyberattacks more potent, scalable, adaptive, and difficult to anticipate or contain.
These developments have renewed conversations about the harms arising from the use of AI in financial services. As policymakers and researchers parse an expanding range of AI-related harms across sectors, it is becoming increasingly clear that harms arising from AI in finance may emerge through two distinct causal mechanisms.
The first category consists of harms that arise when AI is used to make or support financial decisions — use-bound harms.
Financial service providers are increasingly experimenting with AI in the design and delivery of financial services. Early applications largely focused on underwriting using alternative datasets, sometimes collected through IoT-enabled systems. Over time, use cases have expanded to include customer support and grievance redress through conversational interfaces, portfolio optimisation, robo-advisory services, advanced underwriting models, fraud detection, and regulatory compliance systems powered by large and small language models.
Harms arising from such uses of AI are often bounded by the use case itself. They may manifest through bias, discrimination, opacity in decision-making, denial of effective redress, exclusion, financial loss resulting from autonomous actions, or misinformation generated by AI systems. These harms are “localised” in the sense that their effects may not extend beyond the specific function being performed. However, because these systems are often deployed at scale, even localised failures can produce widespread customer harm.
The growing prominence of Responsible and Trustworthy AI (RTAI) frameworks reflects increasing recognition of these harms. Contemporary RTAI approaches recommend safeguards across the lifecycle of AI systems to ensure explainability, transparency, contestability, auditability, and human oversight, while reducing the potential for bias and discrimination.
The second category consists of harms that arise when AI is used to attack financial systems — cyber-offensive harms.
In contrast to use-bound harms, these harms emerge when AI is deployed as part of offensive cyber strategies designed to exploit vulnerabilities in financial infrastructure. Advances in generative and Agentic AI have significantly enhanced the capabilities available to cyber attackers.
Harms arising from such uses of AI are best understood as an evolution of existing cybersecurity harms, but one that radically improves the speed, scale, sophistication, and adaptability of offensive capabilities. While policymakers and industry actors are still grappling with the implications of such developments, these shifts are likely to accelerate a transition toward AI-enabled cyber defence frameworks focused on systemic resilience, continuous monitoring, and dynamic stress-testing, rather than reliance on periodic audit-based approaches alone.
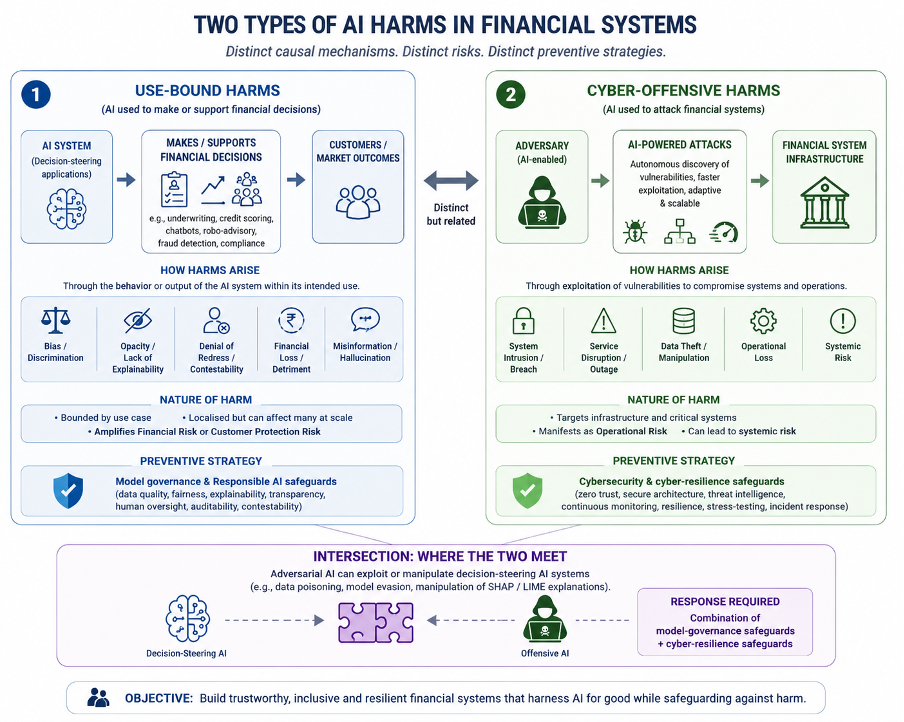
Figure :1 Conceptualising AI-related harm.
This is an AI generated image based on the authors’ content
The distinction between these two causal mechanisms is important because each calls for a different preventive strategy.
Use-bound harms arise when AI systems amplify financial harms or customer protection harms, for instance through discriminatory lending, opaque underwriting, or procyclical decision-making. Preventive mechanisms in such cases focus on ensuring that algorithmic systems behave as intended, remain interpretable, and are subject to effective governance and oversight.
Cyber-offensive harms, by contrast, target the infrastructure underpinning financial systems and manifest primarily through operational risk. Here, preventive strategies emphasise strengthening cybersecurity architecture, improving resilience, and building the capacity to withstand increasingly sophisticated exploit capabilities.
Importantly, these categories are not entirely distinct. The two can intersect.
Autonomous offensive AI systems may exploit vulnerabilities in decision-steering AI systems themselves. Researchers have already pointed to the possibility of adversarial manipulation of explainability artefacts such as SHAP and LIME scores, thereby undermining the interpretability mechanisms relied upon for model governance and oversight. In such contexts, preventive and mitigative strategies will necessarily combine both model-governance safeguards and cybersecurity measures.
This series examines these different causal pathways of AI-related harm and the policy questions they raise. It is intended as a primer that introduces emerging issues and evolving policy approaches, rather than as a definitive account of what regulation should ultimately require.
The first piece in this series revisits and reprioritises the policy recommendations put forward by the RBI’s FREE-AI Committee in light of the interaction between decision-steering and cyber-offensive AI. The second examines the cybersecurity risks associated with increasingly autonomous exploit capabilities and assesses whether existing cyber resilience frameworks are adequate to address them.
Given the pace of technological change, we emphasise that this is an evolving area of inquiry, and additional pieces may be added to the series over time. Our earlier work on Responsible and Trustworthy AI focuses specifically on use-bound harms and proposes a practical toolkit for assessing the robustness of model-governance safeguards deployed by financial service providers.
Part 1 of the series is available here
Part 2 will be published soon.

